
Web-UI 自动化实践
- 2020-10-09 15:20:14
- shijian
- 转贴:
- 有赞coder
- 25955
概述
- Bee 是由有赞 QA 开发的 UI 自动化工具,并以此实现了 web 端和 wap 端的核心业务的自动化。旨在简化开源工具提供的接口,方便 UI 自动化测试用例的设计。
- Bee 整个框架是基于 selenium 和 selenide 设计的。框架对 selenium 和 selenide 提供的接口进行了二次封装以满足日常的用例设计,二次封装后的接口解决了一些元素加载,元素定位解析等问题,可以让用例设计变得更加简便。
- Bee 能支持 Web 和 Wap 页面的元素定位以及操作,其中 Selenide 主要支持 Web 页面的元素操作,Selenium 支持 Wap 页面的元素操作。
Bee 为什么会采用 Selenide+Selenium 的模式:
- 原因一:其实框架设计的初衷是想全部依赖 Selenide 来完成 Web 和 Wap 的自动化,Selenide 对于作者来说是一个全新的开源框架,很想窥探一二;
- 原因二:Selenium 可无缝接入。在实践过程中发现 Selenide 还不能支持 Wap 页面,满足不了日常的测试需求,好在框架可以很容易的嵌入 Selenium 从而实现了 Wap 页面的自动化,也正是 Selenide 和 selenium 有这个特性,所以在框架设计初期才敢放心的尝试采用Selenide;
- 原因三:在实践中的切身体会 Selenide 对页面元素的处理会比 Selenium 平滑的多,因为 Selenide 其本身也是对 Selenium 的一个二次封装,对 Selenium 的接口也做了很多的优化。
用例设计
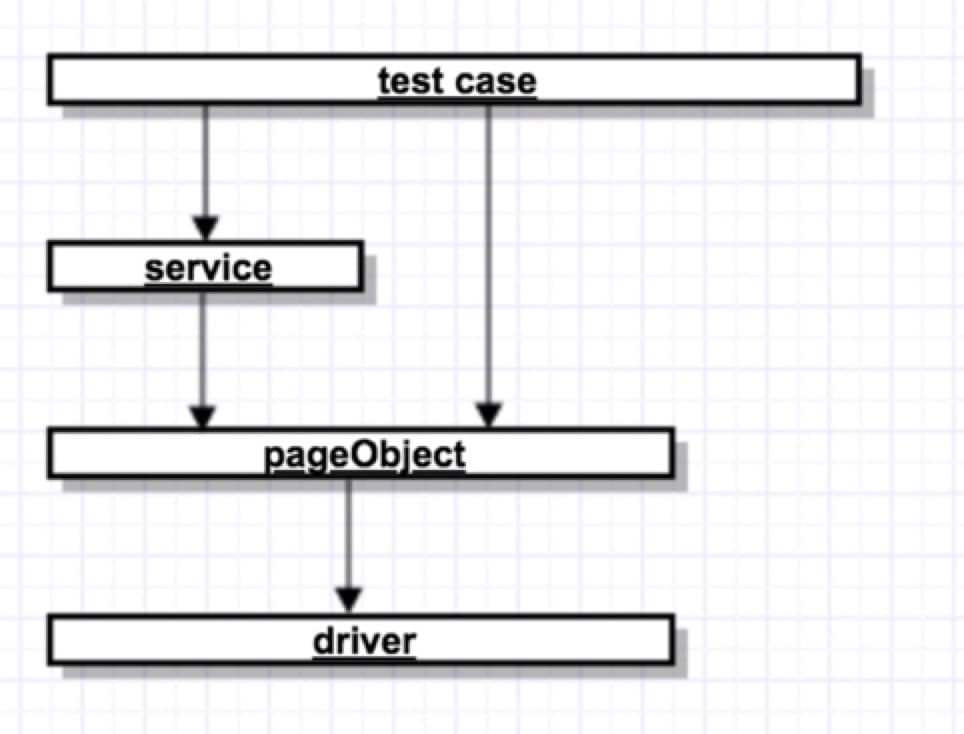
按照实际的业务流程调用对应接口来实现 WEB-UI 自动化测试用例。case 层可调用 service 层和 pageObject 层的接口,pageObject 是对每一个页面元素的一个封装,service 是对一个常用的业务模块功能的封装。比如一个营销秒杀的测试用例,需要依赖登入、创建商品,这两个业务功能就可以直接调用 service 中的接口。秒杀活动的创建就可以调用 pageObject 中的接口,然后按照秒杀的业务流程,在测试用例中把这些接口串起来就形成了一个 UI 自动化测试用例,详细细节接下去会举例说明。
设计用例的灵活度取决于 pageObject 封装的颗粒度,颗粒度越小越容易在用例层设计出新流程的测试用例。用例层使用了 testng,可按照实际的需求灵活设计一个测试用例。推荐在封装 pageObject 接口的时候,颗粒度定义的越小越好,方便用例的扩展和维护。pageObject 封装的接口就相当于一个原子,原子粒度越小越方便组装成新的用例。相反如果粒度太粗维护上会不太方便。参考代码:
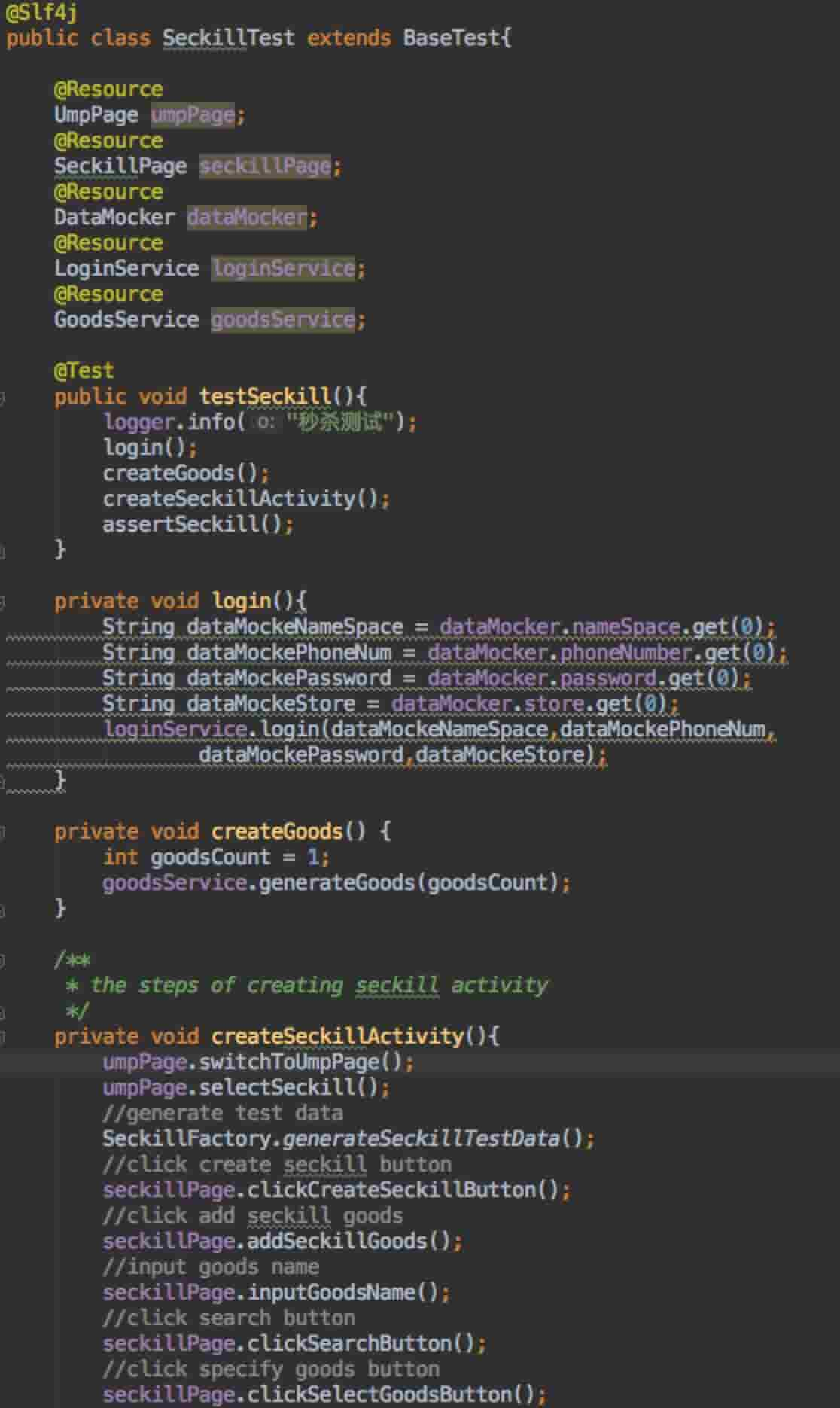
- 创建活动之前,需要登入有赞微商城后台,登入操作已封装到 loginService,直接调用 service 层的接口,不需要在意这个步骤的细节;
- 登入之后要指定一个商品参与秒杀活动,普通商品创建已封装到 goodsService,直接调用 service 层的接口,不需要在意这个步骤的细节;
- 接着是创建秒杀活动,创建秒杀活动的所有业务步骤都封装到 seckillPage,这就是个 pageObject 的实现,也是用例设计中最主要的环节;
- 最后把这几个步骤串起来就形成了一个秒杀活动的测试用例。用例结构清晰,组装简单。
框架介绍
1、工程结构
整个工程基于 selenide & selenium,采用 pageObject 模式搭建起来。技术结构:selenide+selenium+testng+reportng+spring。下面对工程中的几个重要模块做介绍。
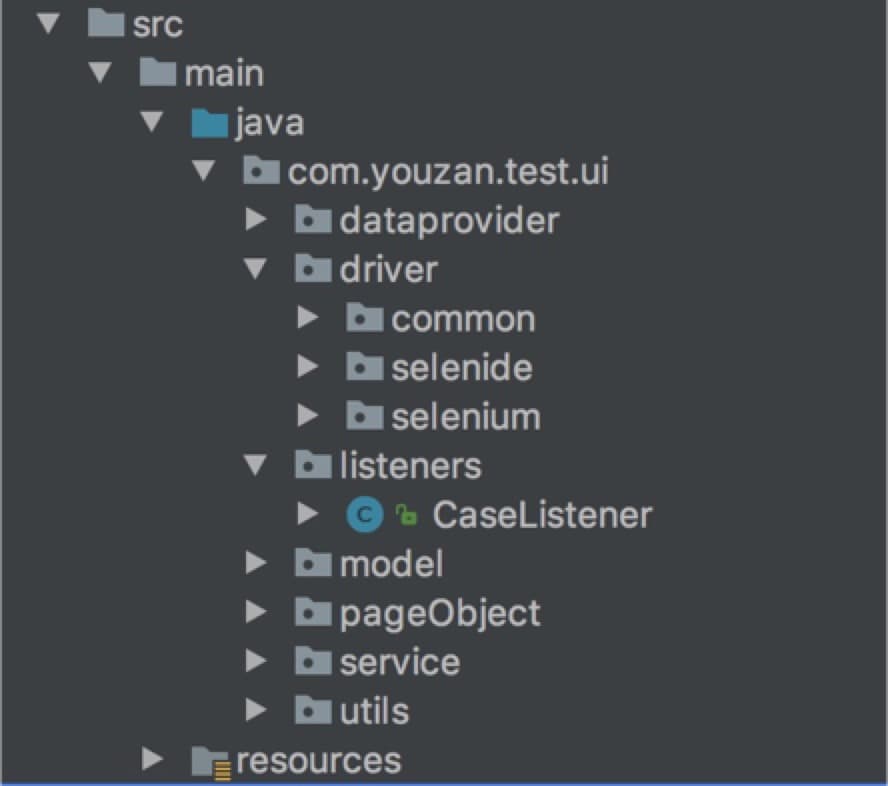
1.1 dataprovider — 数据层
为了实现测试数据和测试用例分离而采取的一种方法,数据模型在 model 中定义,具体的测试数据则在 dataprovider 中初始化。1.2 driver — 接口层
对 web 页面所有元素的操作都是在这里定义接口并实现的。driver 对 selenide&selenium 提供的接口做了二次封装,对外提供封装后的接口。common 实现了一些和接口相关的公共方法,比如模拟键盘按钮等,目前 common 封装的方法不多,大多功能都可以通过 selenide&selenium 实现。driver 层对开源工具接口做了二次封装,想要驱动一个浏览器还有一个必不可少的工具 —— 浏览器驱动,这个驱动放在 resources 里,驱动的版本必须与被测浏览器版本相匹配。1.3 listeners — 监听器
为了提高框架本身的容错能力监听一些事件。目前实现了:1. 监听用例测试结果,可对不同的测试结果监听器做不同的处理;2. 失败测试用例重试的监听,一个 fail 的用例最多可重试3次。1.4 model — 数据模型
为了实现测试数据和测试用例分离而采取的一种方法,具体的测试数据在 dataprovider 中初始化。可以对一个业务流程中需要测试数据的元素在一个 model 中定义出来,方便管理和代码阅读。1.5 pageObject — 业务层
pageObject 模式,接口形式封装每一个页面需要用到的元素,实现上只要做两步:确定元素的定位方式;调用 driver 中对应的操作接口。driver 的接口实现包含了一定的容错能力,但并不是全面的,有些页面独特性或者组件的独特性单纯调用 driver 的接口并不能保证测试用例的稳定性,此时就需要在 pageObject 的接口实现中加入一些容错算法,确保用例稳定性。
实际操作的经验是 pageObject 对元素封装的颗粒度越小,在用例设计层设计测试用例就越灵活,可以像组装工具那样组装出一个新的测试用例。参考代码:
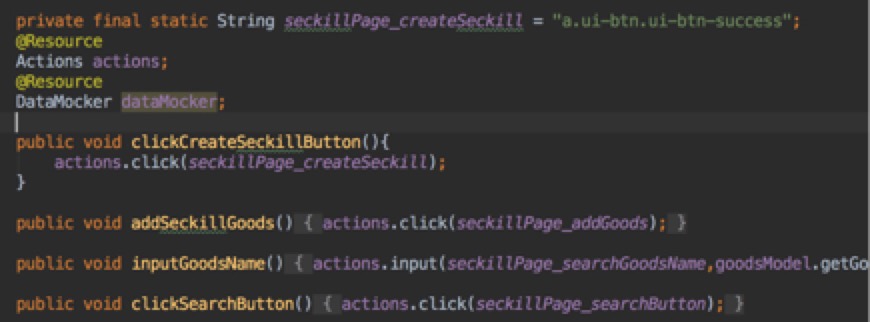
1.6 service — 提供业务功能
一个业务流程很多时候依赖其他业务模块功能,为了方便设计一个测试用例,也为了避免重复造轮子,service 层就提供了一些常用的业务功能,比如登入、创建商品等。依赖方只需要在 service 层调用即可。2、功能优化
Bee 对 selenide&selenium 做二次封装的同时也对接口做了些优化,框架的初衷是使设计一个 UI 用例尽可能的易设计、易读、易维护。2.1 接口优化
直接调用 selenide 或者 selenium 的接口经常会遇到些令人头疼的问题,比如网络问题使页面 loading 太慢,需要操作的元素还没展示出来,这种情况就会经常报元素找不到的 error,用例执行失败,但实际上这种报错不是一个 bug,测试结果是无效的。为了提高误报率 driver 层接口实现了等待元素加载的功能,使用的关键接口:Selenide.$(elementLocator).waitUntil(Condition.appears, timeout)。参考代码:`/**
* 检查元素加载情况
* @param elementLocator
* @param timeout
* @return
*/
private boolean checkElementLoad(By elementLocator, long timeout){
try {
Selenide.$(elementLocator).waitUntil(Condition.appears, timeout);
return true;
}catch (Exception ex){
throw new RuntimeException(ex);
}
}
/**
* 如果没有找到元素抛null异常
* @param element
* @param timeout
* @param elementType
* @return
*/
private By isElementLoaded(String element, long timeout,String ...elementType){
By elementLocator = null;
int count = 4;
long partTimeout = timeout/count;
for(int i=0; i<count; i++) {
elementLocator = waitingForElementLoad(element, partTimeout, elementType);
if(null != elementLocator){
break;
}else if (null == elementLocator && (count-1) == i) {//元素为null抛出异常
log.error("Web页面元素:{} 无法定位",element);
}
}
return elementLocator;
}`
概述中提到过 selenide 本身就是对 selenium 的一个二次封装,所以 selenide 对元素的操作会比 selenium 平滑的多。在页面加载方面 selenide 本身有做优化,再在 click、input 等操作接口中加入 waitUntil 的判断可最大限度的等待一个元素的加载从而提高测试用例的稳定性。
2.2 元素定位统一入口
接触过 UI 自动化用例设计的同学会比较清楚,想通过 selenide&selenium 操作一个元素,其中必不可少的就是对元素定位的描述,通俗的讲就是要通知接口在当前页面操作哪个位置上的元素。定位一个元素的方法很多,常用的有 id,name,css,xpath 等,对应不同的定位方法 selenide&selenium 在处理上也给出了不同接口。这从维护角度上来考虑显然不是最好的。最好的做法就是用例设计者只管元素定位和操作事件的调用,而事件实现上走了哪种渠道最好是无感知,无需维护的。对此框架封装了一个方法供 driver 调用,主要功能就是解析描述元素的字符串自动判断是 id、css 还是 xpath。2.3 失败测试用例重试
网络原因等不确定因素会导致测试用例失败,这种外部因素导致的失败一般都会认为它是无效的,为了提高测试报告的可信度,增加了失败用例重试的机制。具体做法是实现一个用例测试结果的监听器,当监听器监听到一个 fail 的结果,会触发重试,失败用例最多重试 3 次。3、元素定位
UI自动化用例其实可以分成两部分,1. 定位元素;2. 调用接口操作该元素。其中定位一个元素的方法很多,常用的有 id,name,css,xpath。实际设计中选择哪种定位方法一般会在维护角度上考虑的会多一些,因为现在的服务器性能配置等都很优秀,所以跑一个WEB-UI用例可以不用考虑性能问题。从维护成本上考虑会优先选择 id、name,其次 css,最后用 xpath。我们并不能保证每一个 web 系统的所有元素都能给你提供一个唯一 id 或者唯一的 name,当然如果能和前端开发达成合作这就是一件很美好的事情了,一般情况下我们都需要面对没有 id 和 name 这两个属性的情况。这时我们就可以使用 css 样式,很多时候 css 样式是能满足我们的定位需求。
当然在这些都不提供给我们的情况下就只能选择 xpath,使用 xpath的 优点:
- 易获取,主流浏览器只要打开“查看”就可以通过 copy 轻松获取到;
- 页面上的元素都可以用 xpath 来描述。
缺点:不稳定,大量使用的话会给用例维护产生很大的负担。
xpath 一般只要前端在页面上做一下小调整用例就必须重新维护,在不得不使用 xpath 的情况下为了减少今后的维护量可对 xpath 做一些优化,可以减少 xpath 的路径长度提高稳定性。以下是实践过程中最长用到的几种类型:
- 依靠自己的属性文本定位,如 //input[@value=‘XXXXX’]
- 包含指示性字符,如 //input[contains(text(),’指示性字符’)]
- 巧妙使用 descendant,如 //*[@id=‘app-container']/descendant::input
CI集成
用例设计完成之后就可以加入集成建设,让UI自动化用例在集成环境中发挥作用。测试报告展示使用 reportng。jenkins 的插件可以很好的把 report 呈现出来,所以 reportng + jenkins 是一个很不错的组合。
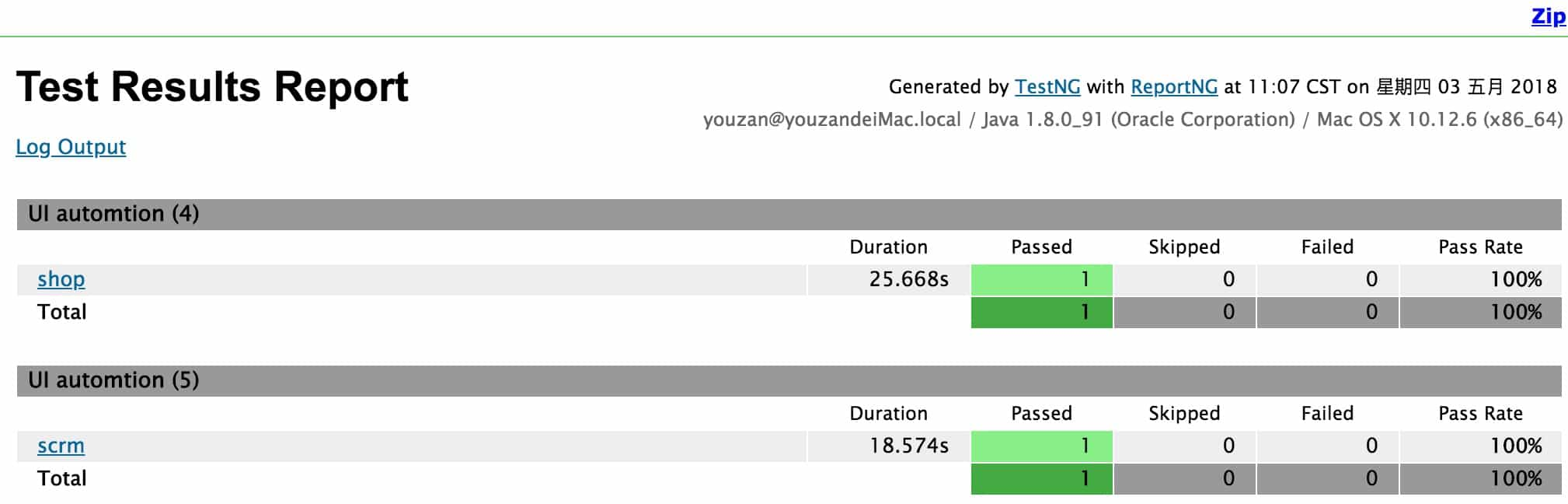
搭建的步骤:
- 搭建一个 jenkins。
- 一台用于跑 UI 自动化用例的服务器。
- 将服务器配置成 jenkins 的一个节点。
- jenkins 创建 job,job 中需要使用的插件包含 Git、Excute shell、Editable Email Notification、Publish HTML reports。其中 editable email notification,支持邮件提醒,是个很不错的插件。支持 html report 格式,附件功能。
常见报错
使用 Bee 过程中经常会遇到些问题,这里做下总结方便 debug。- 某些页面不滚动。有时候一屏展示不了所有的元素。理论上 selenide 或者 selenium 在一个页面中查找一个元素是可以自动执行滚屏,但有些时候滚屏会失效,此时就需要在测试用例中实现滚屏查找元素。 解决方法:void scrollToElement(String element,String …elementType)
- 有些输入框不能被 input 接口正常操作。实践过程中在日历控件中遇到过,元素定位什么的都对,但就是不能正常被操作。 解决方法:void triggerInput(String element,String …elementType),该接口起到一个触发的作用,实际操作中遇到类似的情况可以把它当做一种尝试。
- 按钮不能被 click 接口正常操作。button 元素定位完全正确。且在“检查”窗口中看到的也是 button 属性。
<button type="button" class="zent-btn-primary zent-btn-large zent-btn">确定</button>
解决方法:调用接口 void clickByText(String text) - 发现 selenide 或者 selenium 的某些接口不能 work 了,此时最大的可能就是浏览器升级了。 解决方法:升级浏览器驱动
- 元素不可见。有一种元素能在页面上正常展示但对于工具来说它是不可见的,这是因为在一般情况下元素可见需要满足以下几个条件:visibility!=hidden ; display!=none; opacity!=0; height、width都大于0;对于 input 标签,没有 hidden 属性。如截图就是 opacity=0 的实例。 解决方法 :调用接口 void clickByJs(String element,String ... elementType)

结束语
Bee 是在开源工具的基础上做了些优化,目前为止 Bee 更多的是在 driver 层做了些努力,数据层、业务层以及用例层的解决方案还有很大的提升空间。实现一个 WEB-UI 自动化用例主流的方法有录制和代码实现这两种,其实两种方法各有优劣。
- 联系人:阿道
- 联系方式: 17762006160
- 地址:青岛市黄岛区长江西路118号青铁广场18楼
