
通用性接口健壮性扫描方案
- 2022-07-22 10:00:00
- wangxingqin
- 转贴:
- 有赞coder
- 11739
一、背景
1.1 业务背景
随着公司业务的快速发展,需求越来越多、迭代越来越快,在有限的测试人员和时间投入的前提下,如何做好质量防控,如何提高测试效率,是大家持续思考的问题。
公司业务越来越复杂,应用越来越多,接口越来越多,接口的参数也越来越多,如何做好接口测试?如何做全接口的每一个参数的测试?
在测试过程中,测试人员主要面临以下问题:
- 测试人员都把精力放在核心的业务测试上。很少腾出时间来关注接口的各种参数类型的测试。
- 接口越来越多、接口参数也越来越多,很难做到每个接口、每个参数的穷尽测试。
- 针对接口参数设计的测试用例,用例数量通常都很多,如果只靠人工投入,会大大增加测试人员的时间成本,降低测试效率。
- 测试人员核心关注点在正常的业务数据上,非正常业务数据相关的逻辑很少考虑周全,比如最大值、最长字符、特殊值等。
面对以上的问题,如果所有的测试都靠人工来完成,那将是很大的一笔人工和时间开销。是否可以自动化构造测试数据来自动化部分测试类型,将是本文解决的问题。
1.2 本文解决的问题
为了解决上述问题,本文介绍了通用性接口健壮性扫描方案。本方案也为质量保证、高效测试奠定了基础。
该方案重在忽略业务之间的差异,主要解决了以下问题:
- 建立通用的规则来生成测试用例
- 解决通用性接口测试问题,比如边界值、最大值等
- 全自动化生成、执行测试用例,整个过程无需人工参与,节约成本
- 根据特定的产品规则,解决产品上的共性问题
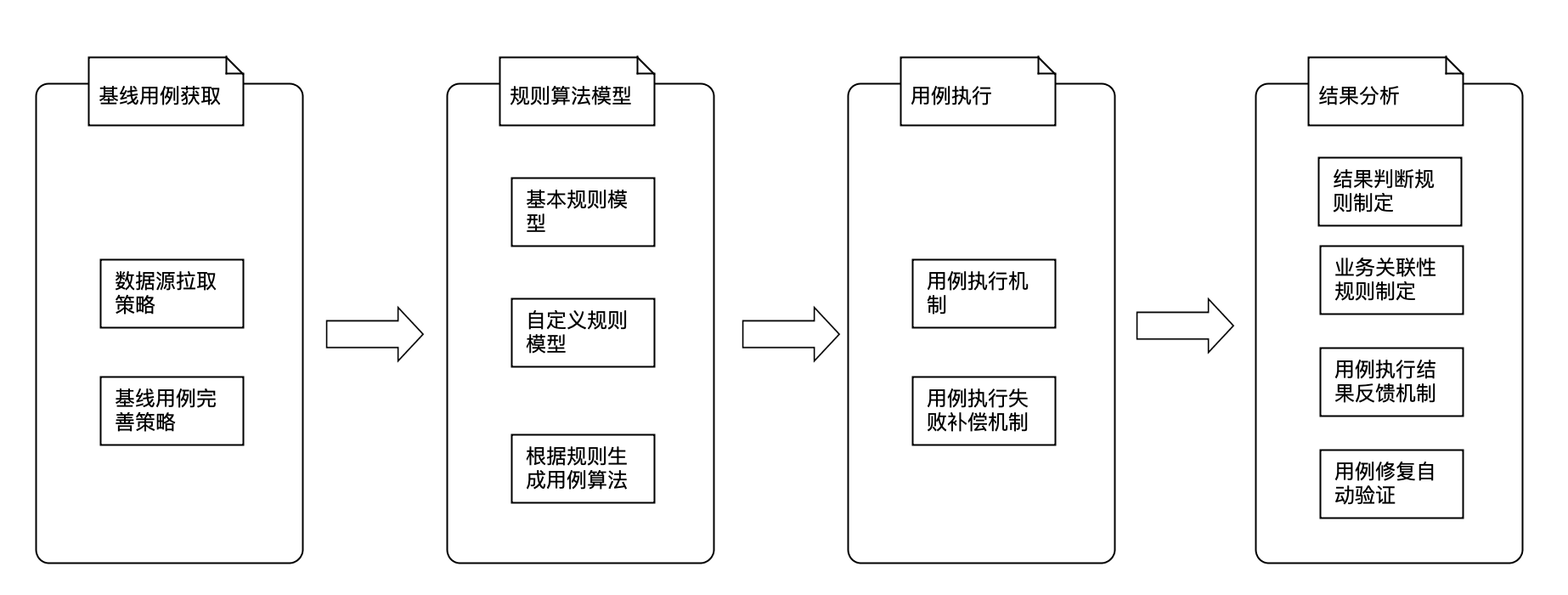
二、系统设计
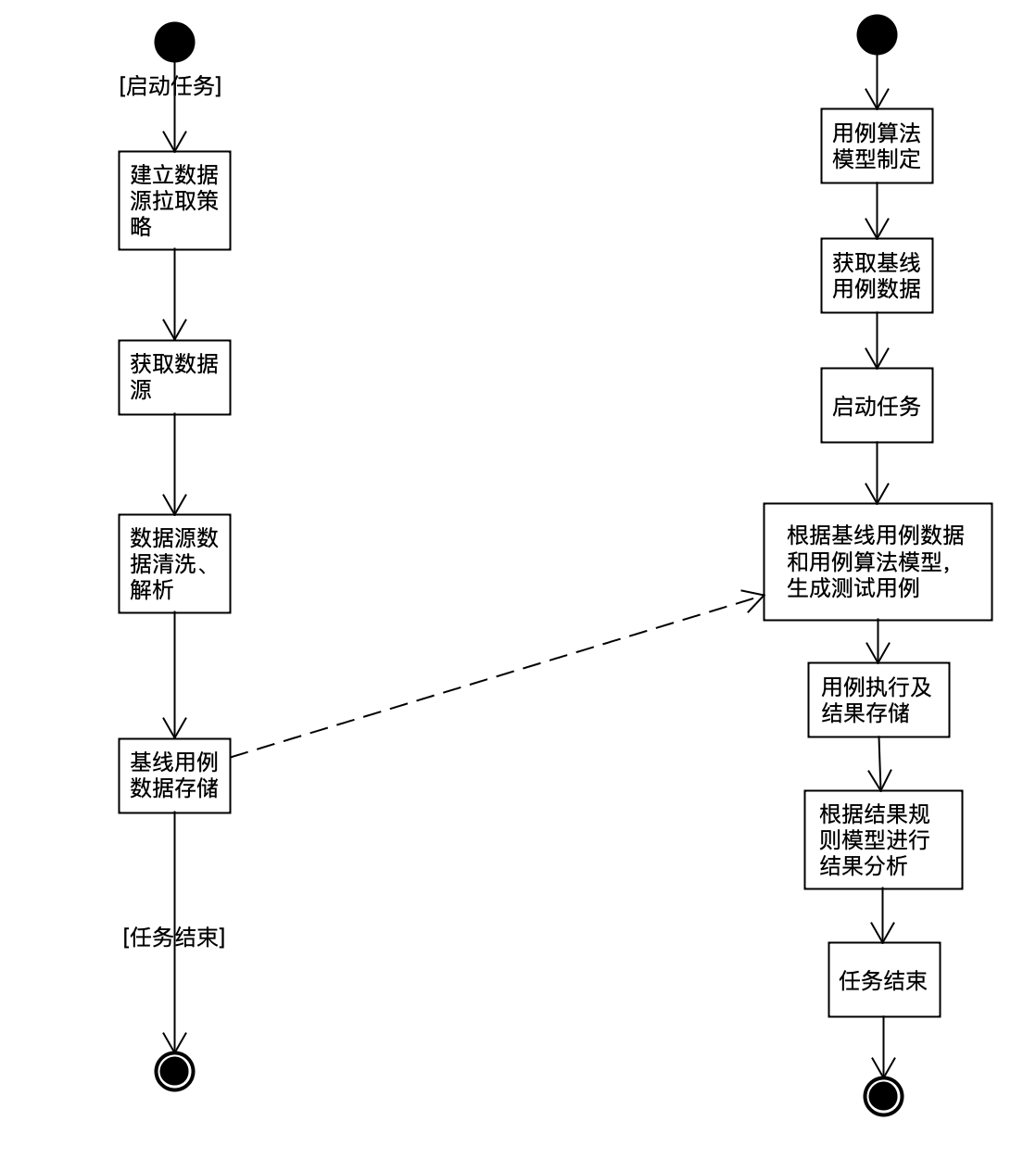
测试的执行过程一般分为三步:生成测试用例、测试用例执行、测试结果分析。通用性接口健壮性扫描主要围绕这三个过程展开。主要分为以下几个核心流程:
-
数据源数据拉取及处理:该步骤基于各种平台,比如网关、流量回放等,主要为了获取基线测试用例。
-
用例规则模型建立与用例生成算法制定:制定通用性用例规则模型,同时也扩展了自定义用户规则模型,根据对应的算法,比如字段的Empty与非Empty,字段的NULL与非NULL,特殊值制定等比如字符型参数最长字符,数值型参数最大值、最小值以及通用性的特殊值等,生成用例数据。
-
用例执行:根据基线测试用例,会获取到对应的服务、方法、测试环境。根据2的模型与算法,生成所有的用例数据,然后进行接口的调用及记录执行结果。
-
结果分析:通用性接口健壮性扫描方案,对结果也是进行无业务逻辑的通用性的结果分析。这里包括结果规则模型的确定与结果分析,剥离出有问题的测试用例结果并自动反馈。
整体流程图如下:
2.1 数据源解析
整个设计的基础是基于基线测试用例。为了获取基线测试用例数据,需要建立数据源拉取策略。数据源来源于以下平台:网关平台、流量回放平台等。
网关层数据的数量巨大,如果拉取数据量过多,会导致拉取时间过长,很容易失败。同时如果多个应用或者多个线程同时拉取,很容易出现并发问题导致数据源拉取失败。
为了避免大量的无效数据源数据拉取,首先建立数据源数据拉取策略,争对性的拉取数据。同时为了避免数据量过多而导致拉取数据失败,设置了每30min拉取一次数据,如果本次拉取失败,则任务重试N次,成功则停止拉取,N次失败后在不在拉取。
获取数据源后,即可对数据源进行解析。通过数据源数据,解析出对应的应用、服务、参数类型、接口参数等,通过接口参数来获取基线用例数据。因为整个公司的应用很多,所以,根据配置策略,只解析在系统里配置过的应用数据,过滤掉没有配置过的应用的数据。下面是整个数据源的拉取与解析流程图。

网关平台的数据源只包含网关层的信息,并不能获取到后端的服务信息。我们的调用是基于dubbo服务的调用,所以还需要通过有赞网关平台,查询并获取到对应的dubbo服务的名称、方法、参数类型、返回值类型等信息。然后根据网关的参数,组装成dubbo服务的接口参数,最后把这些数据进行持久化存储。
为了丰富基础用例数据,后续会接入多种平台,获取更多的数据源数据。
2.2 用例数据生成算法模型
本篇文章的核心在于建立通用性用例数据生成的算法模型。核心流程如下:

首先建立基本的算法模型,主要包括基本的规则以及按照规则生成用例数据的算法。同时还扩展了用户自定义规则,根据用户自定义规则来生成对应的用例数据。
下面简单举例NULL规则生成的数据用例过程:
下面简单举例NULL规则生成的数据用例过程:
上述的NULL规则用例生成具有很好的通用性。EMPTY规则生成和NULL类似。特殊值类型的规则制定,尤其是特殊值的制定,除了使用通用性的数据规则之外,如Double.MAXVALUE,Integer.MAXVALUE等,还可以使用业务上的通用性特殊数据。具体如何制定特殊值,需要根据业务来分析。
特殊值规则制定好之后,则根据参数类型,用指定的特殊值去替换,生成对应的测试用例。假设这里指定如下特殊值:Integer.MAX_VALUE与String.maxLength("AAA.........")。最后生成的用例如下:
上述两种都是通用的规则算法,实际应用中远不止这些,有很多需要根据业务规则来确定规则模型。自定义算法模型就是根据用户自定义规则来生成对应的数据用例,增加了模型建立的灵活性。每个模型都有各自对应的生成算法,每个模型需要实现generateCases方法即可。总的获取所有模型用例算法流程如下:
应的生成算法,每个模型需要实现generateCases方法即可。总的获取所有模型用例算法流程如下:
2.3 用例执行
特殊值规则制定好之后,则根据参数类型,用指定的特殊值去替换,生成对应的测试用例。假设这里指定如下特殊值:Integer.MAX_VALUE与String.maxLength("AAA.........")。最后生成的用例如下:
2.3 用例执行
数据用例生成后,即可进行用例的执行。为了和数据源拉取任务错开,也是每隔30MIN执行一次,但是执行的时间段数据比日志拉取的时间早30min。比如数据源拉取时间为当前时间的前30min,则用例执行的时间为当前时间的前60Min。主要是为了避开数据源拉取任务的数据还没拉完,导致用例漏执行。具体执行流程如下:
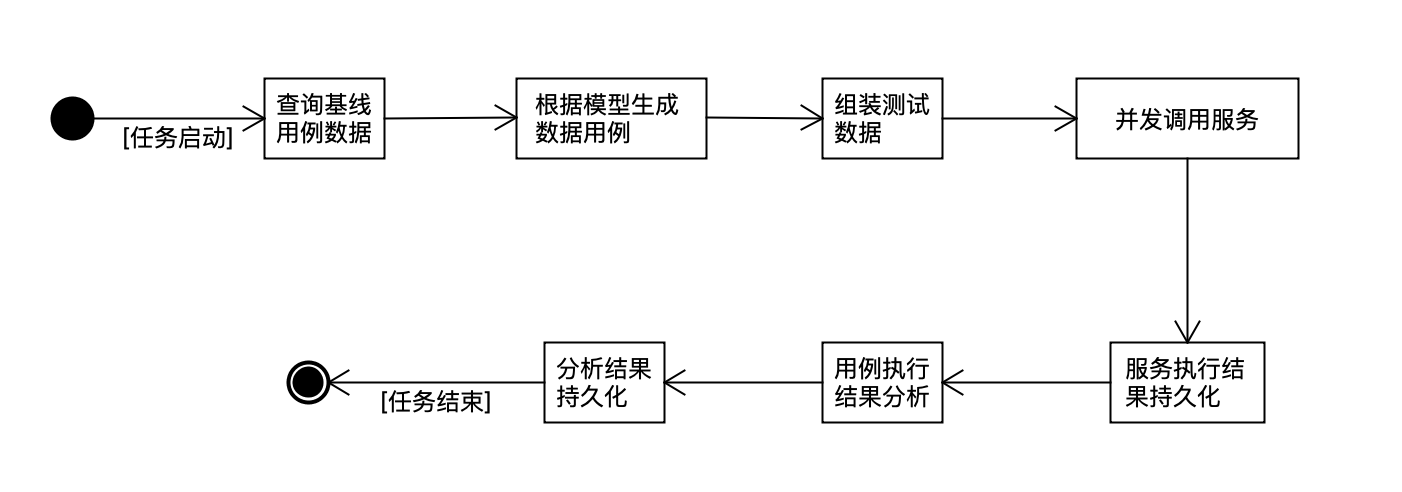
根据算法模型生成的用例数据量一般都比较大,为了加速执行过程,采用多任务执行。服务调用可能会出现失败情况,如果失败,则根据补偿机制来重试,最终确保每个数据用例都能执行完成。补偿机制过程如下:

2.4 结果分析
通篇最难的是如何进行结果分析,即如何判断执行的结果是有问题的。主要有两种情况:1)返回success的接口实际上是错的不符合预期的;2)返回非success的接口实际上是正确的符合预期的。所以结果判断规则的制定特别重要,直接关系到结果判断的准确性,即整个方案的可行性。
目前争对方案能解决的问题,主要制定两种类型的错误提炼规则:一、判断错误提示不合理;二、判断后端执行结果不合理。
1) 错误提示不合理
问题背景:商家在使用我们的产品的时候,会报一些错误。但是有些错误,商家会看不懂,不明白其中的意思,比如下图的错误提示。
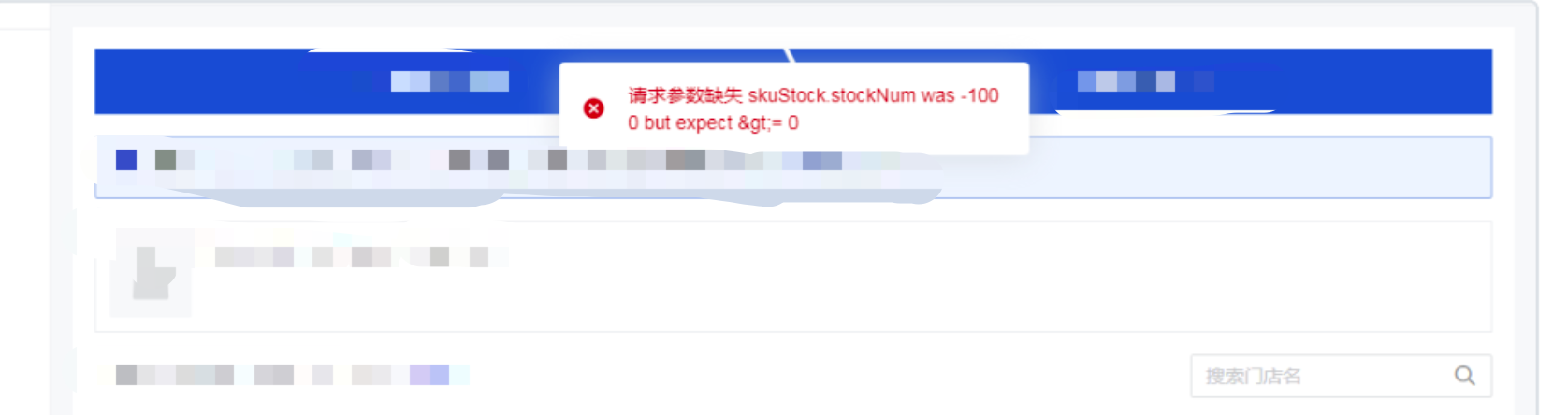
解决方案:为了解决此类问题,展示给商家的更友好的错误提示,提炼了错误提示不合理的规则,自动判断接口返回结果不符合规则的用例。
这种规则的前提是基于接口返回的结果是非success。如何确定呈现给商家的错误提示不合理,需要测试、开发、产品人员一起确定出来“什么样的提示规则是合理的、商家易理解的”。比如呈现给商家的错误提示遵循一定的格式,呈现给商家的错误文案里一定不能包括专业性的词汇、不能包括一连串的英文、数字、不能包括传参对象的属性名称,呈现给商家的错误提示文案必须是完整的一个句子等等。根据这些规则,制定代码提炼错误的规则,即可准确判断出接口错误提示是否合理。
2) 后端执行结果异常
问题背景:商家在使用我们的产品的时候,系统会出现不可预知的异常,这些异常都是代码逻辑错误导致的。这类异常提示一般都有明显的特征,比如服务器错误、业务异常、远程调用异常等。
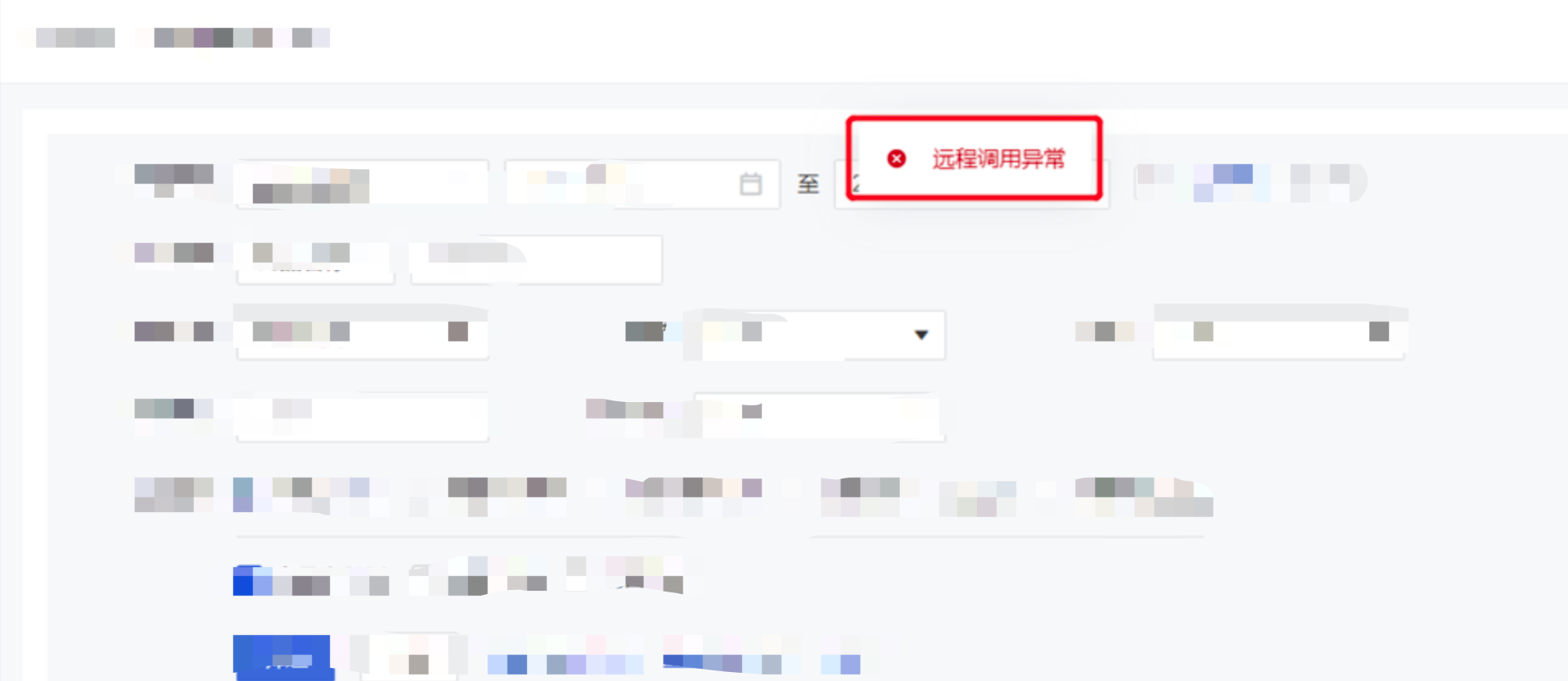
解决方案:为了解决此类问题,抽取了几千条结果数据,这些测试数据基本覆盖了大部分的应用。争对这些数据,找出这类错误的结果提示,制定成一个规则集合。满足规则集合的则认为是有问题的用例。
这种规则的制定,需要采集各个应用的大量的结果数据,找出这类型错误的提示,加入到规则集合中。一旦抛出这种错误,我们就认定用例结果一定是异常的、不合理的。这种规则的集合,需要持续性的维护,并且需要制定好开发规范。后续开发遵循这种规范,不能随手拈来一个错误提示。
三、总结与展望
通篇介绍了通用性接口健壮性扫描的方案,基本能够自动化解决部分接口通用性问题,整个过程无需人工干预,节省了不少人工成本,提高了应用的健壮性等。主要表现在:
- 自动化获取基线用例
- 自动化生成用例数据,这个数据量更丰富,数据更完善,基本能够覆盖所有场景的接口参数数据,做到穷尽测试
- 自动执行用例,输出结果
- 自动进行结果分析,判断出有问题的用例
- 自动生成jira,自动推送给开发修复
- 开发修复后可以人工点击重试,既可验证修复结果,无需重新构建用例,无需人工去调用。
此方案忽略了业务之间的差异,扫描出的是通用性的逻辑问题。对于结果分析,还存在一定的弊端。比如期望结果是非success的,但是返回的结果却是success的。这种还没有确定的规则去挖掘出这类型的问题。因此,后续还有无限的提升空间。
后续可以朝着这几个方向优化:
1)做到业务关联性
目前是忽略了业务的差异性,但是还有很多和业务相关的通用问题,暂时还无解决方案。是否可以建立业务关联性,来解决更多的问题。
2)结果精确性规则提炼
目前的规则制定,都是在有限的用例测试样例数据上提炼出来的。制定完善的规则,需要更多的测试数据来分析。同时,也需要良好的开发规范来保障后续提示遵守这个规则。这两者是相辅相成、相互促进、相互完善的。
3)解决“返回success的接口实际上是错的不符合预期的”问题
返回success的接口实际上是错的不符合预期的,目前这类问题还无法判断。4)基线用例持续性完善
最初的基线用例数据可能只覆盖了大部分的参数,但是并不能保证覆盖到全部参数。因此基线用例的完善也是需要一个规则来持续性优化。
结合现在的设计,最终未来呈现出的方案会包括以下核心的流程:

- 联系人:阿道
- 联系方式: 17762006160
- 地址:青岛市黄岛区长江西路118号青铁广场18楼