
自动化接口测试实践经验
- 2022-01-04 08:34:00
- faithchen
- 转贴:
- 公众号
- 11864
作者:faithchen,腾讯 PCG 测试开发工程师
一、背景
自动化测试对于我们提升研发效能、CI/CD(持续集成/持续交付)是不可或缺的部分。在后台自动化测试中,接口测试尤为重要,它能够保证被测后台服务的质量,以及接口逻辑的正确性等,帮助我们快速测试功能、提高测试覆盖率、把控质量风险等。
1.1 后台接口测试
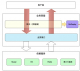
接口测试是功能测试的一种,是测试系统组件间接口的一种测试,重点在于检验对于服务接口的数据交换的正确性,一般全部依赖真实链路,测试时需要启动被测服务。如下图是某个Server A的接口测试:

然而,写过接口测试的同学可能都会被复杂的数据构造以及繁杂的断言所困扰,可能需要耗费大半天才能写完一个接口测试用例,浪费了许多宝贵的时间!基于以上考虑,为了提高编写接口测试用例的效率,我们希望能够自动化地协助开发或测试人员完成这些耗时耗力的事情,为此而产生的想法是通过流量的录制,再通过录制的流量自动化生成接口测试用例。基于上述想法,我们提供了从录制流量到生成接口测试用例完整链路的工具,辅助开发同学快速完成编写接口测试用例。简单来说,只需要以下三个步骤便可以接入:

接下来,我们通过**“流量录制->生成用例”的流程来进行阐述我们的实现方法和接入方式。我们会说明通用的平台如stke、sumeru服务的接入流程,由于123平台对goreplay等有较好的支持,除了通用流程外会以123平台为例进行说明。最后会说明流量频次筛选方案**帮助大家理解我们的流程。
二、流量录制
2.1 流量录制简介
2.1.1 什么是流量录制
我们听得比较多的是“录制与回放”,但目前只需要用到录制功能,后续可能会把回放功能也加上。顾名思义,流量录制就是指将我们期望的接口数据的包括response、request、协议等等存储起来的操作,可以是正式环境或者是测试环境的数据,开启了录制功能后,只要对应环境的服务有流量,便可以将其捕获存储起来,实现此功能的方式有多种。
通过对多个方案的对比后,我们决定采用goreplay的方式,其开源代码是goreplay ,基于goreplay 1.2.0版本改造后已经支持trpc, http, gofree, wup, videopacket, 后面会陆陆续续支持其他协议,采用goreplay的主要优势是它可以分析和记录服务的流量但不会影响服务,并且接入流程相对简单。
goreplay方案其最大好处是与业务代码解耦,不需要入侵代码。

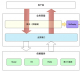
在传输层的goreplay录制方式为:

2.1.2 为什么要进行流量录制
接口测试是在真实运行的服务中测试,若想自动化生成用例,理想的情况下,便是要自动化生成真实数据的接口测试用例,那么首先需要的就是真实的接口数据,数据从何而来呢?自然而然的,我们便会想到到线上去录制(无论是测试环境或者正式环境的)。
下面为「通用流程」讲述如何为服务接入goreplay流量录制流程。
2.2 「通用流程」服务流量录制
2.2.1 「通用流程」上传pb文件至协议中台用于解析二进制流量
首先我们需要一个能够管理协议的系统,它能够对协议文件(如pb文件等)进行管理,这样当协议有更新时,依然能够对新的协议生成的流量进行解析。
能够将goreplay录制的二进制数据进行解析:

2.2.2 「通用流程」生成并执行goReplay命令
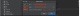
在上述协议中台获取了版本号之后,我们已知后台服务的ip和端口,已经最新的协议版本。将这些填入我们的goreplay命令中,如下图所示:

将上述命令在对应的容器中执行。
部分参数说明:
<code>--input-raw-logreplay// 这个其实是rawInput插件的参数, 开启这个参数后, 必须ip和port都要填 --output-logreplay-cache-size 200// LogReplayOutPut插件 需要的缓存大小, 可以不设置, 有默认值 --output-logreplay-track-response// 跟--input-raw-track-response含义一样 --input-raw-protocol // 必填需要解析的协议 --output-logreplay-protocol-service-name "app.server" // 协议文件对的服务名 --output-logreplay-commitid "1.0.1" // 必填,如果是http协议, 可以自定义 --output-logreplay-qps-limit 100// 限制录制的qps, 非必填, 有默认值 --output-logreplay-env formal // 选填,默认formal,需要注册到logreplay测试环境可填test</code>
在容器中执行ps -ef|grep goreplay
看到如图进程便表示成功了:

2.2.3「通用流程」查看录制流量
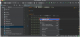
当服务在对应环境有流量的话,很快我们就可以查看到通过goreplay录制到并解析成功的流量了。
里面的request和respond等数据都一目了然(此处是demo所以数据很少,真实环境中,可能有非常多的参数及数据),根据这些录制的数据,我们下来就可以自动生成接口测试用例了。
三、生成用例
当录制好流量后,我们会有一个筛选机制来过滤流量,不过这个操作对于用户是无感知的。对于使用方来说,接下来就能够 自动化生成流量了。
3.1 px-cmdline工具简介
我们提供了px-cmdline工具,这是一个命令行工具,它可以将goreplay录制的流量,通过proto文件,自动获取相关依赖后生成符合代码规范的接口测试文件。
3.2 px-cmdline使用
使用方式也很简单,命令行格式为:
px-cmdline generate -p <proto gomod> [-f] [--env test] 常用参数介绍:
- -p 指定proto依赖路径,从go.mod中拷贝
- -f 是否强制更新,开启后,会替换掉即将生成的同名接口测试文件
- --env 指定拉取流量的环境变量,默认test环境
- --dest 指定生成的目录,默认tests文件夹
- -j 指定是否切换json文件模式。默认使用json文件独立模式;开启后,用例写入到*_test.go里
示例:
px-cmdline generate -p git.code.oa.com/xxxxprotocol/hello/world 运行后,如果未发生异常,会在当前目录下生成tests子目录,根据每个RPC接口生成独立的__test.go文件,以及一个唯一的suite_bvt_base_test.go用于启动接口测试。testdata目录存放json格式的用例数据。如图:

当服务有多个运行节点的时候,还支持选择运行节点,以便用于本地调试接口用例时请求该目标。建议优先选择test环境或者开发者的特性环境
[Info] 请选择本地测试目标服务:可只选择环境,或指定节点 [Info] (1) 测试环境 test -------- [Info] (└ 11 ) 9.2.3.4:16916, Development, 权重100, 健康 [Info] (2) 特性环境 sdfdfe -------- [Info] (└ 21 ) 11.1.2.3:11389, Development, 权重100, 健康 [Info] (3) 特性环境 dfadfb -------- [Info] (└ 31 ) 9.3.4.5:11042, Development, 权重100, 健康 [Info] (4) 特性环境 c9d193e8 -------- [Info] (└ 41 ) 11.3.4.5:11222, Development, 权重100, 健康>
为了符合代码规范,用例数据目前以json数据的形式进行存储,展示其中一条数据如下:
{
"request": "{\"pp\":[\"1dfa\"]}", "response": "{\"sdf\":{\"TPDKH\":{\"basic\":{},\"cosume\":{},\"data\":{\"type\":\"NotSettle\",\"pll\":[733],\"tpl\":\"UG\"}","trace_id": "394729374872934"
},
如此一来就成功生成了接口测试用例了,当我们本地调试OK后,就可以将其mr进代码主干,在日常流水线运行时都能对接口进行自动化测试。
当然了,如果有同学喜欢用更直观的IDE工具,我们也提供了IDE插件供大家使用。
3.3 px-cmdline 工具(IDE版) Jetbrains 插件使用
如果用户希望通过IDE插件,可以通过如下操作
第一步:我们有相关的插件供安装

弹出窗里面选择刚才下载的ZIP包,然后确定;
第二步:安装完成后重启IDE,启用插件通过插件简单右键选择来生成接口测试文件可以达到与命令行工具同样的效果:


然后便可以顺利生成接口和用例在特定的文件夹中,用于接口测试执行。
四、流量频次筛选策略
本章节补充说明,当我们数据量较大的时候,如何进行筛选与分析,保留下相对有价值的流量用于生成接口测试用例的。
4.1 流量筛选背景
本章节内容讲述我们的流量筛选策略,这部分内容对于使用用户是无感知的,但是有助于对我们工具的完整链路有更好的理解。
当我们为服务接入goreplay后,在服务上有成千上万的流量录制进来,有时候甚至更多,那么怎么知道哪些流量是重复的,哪些流量值得记录下来用于生成用例呢?
由于正式线上环境流量较大,可能存在很多流量数据的重复率和相似度较高的情况,对此,我们不会简单的将所有流量都直接存储到数据后用于后续生成接口测试(毕竟我们也不可能用成千上万个接口用例来测试一条数据),而是会通过一定的策略进行频次筛选,符合我们相似度区分要求的流量我们才会存储到我们的数据库中。
这样做的好处有:
- 防止某些服务流量过大,存储数据过大。
- 剔除重复流量,对于相似度高的流量不重复存储,同时保证了接口测试的数据多样化。
4.2 相似度对比简述
4.2.1 相似度比较总体流程
如下图,例子中有两个流量的response,我们是如何对response或者request的数据进行相似度计算的呢,大致流程为:
-
取其body部分,舍弃header
-
计算一级key相似度,一级key的相似度我们较严格,一般情况下,如果一级key不一样那么则可以认为这两个body之间的差异是较大的,如下图左侧response的一级key有
Msg、ProcId、TaskOutput,右侧response的一级key有Msg、ProcId、Code,显然,我们会认为这两个相似度是较低的,应该是差异较大的流量。 -
假如一级key完全一样的话,显然要进一步递归比较,但是层级越高我们会设置影响因子越小,对此完成相似度的递归计算。

4.2.2 字符串相似度
一般计算到二级key以后,我们便要开始关心字符串的相似度了,此处我们使用的算法是Levenshtein距离 ,定义如下:

简单说来,就是计算一个字符串需要经过多少次编辑才能变成另一个字符串,结合它们的字符长度和编辑次数,我们便可以计算两者之间的相似度。
例如,将“kitten”一字转成“sitting”的莱文斯坦距离为3:
- k itten → s itten (k→s)
- sitt e n → sitt i n (e→i)
- sittin → sittin g (插入g)
当获得字符串相似度之后,进而可以计算出json的相似度即response和request的相似度,再结合多级key的影响因子策略进而计算出两条流量的相似度。
4.3 筛选策略
获得相似度之后,我们还会通过多层策略来筛选。
-
设置response和request的比重,因为通常response更好地反应接口的差异,设置比重可以更好的衡量流量间的相似度,利于后续筛选。
-
设置多层动态阈值,随着数据量的增加,动态调节能够存入的相似度阈值,以便更好地控制记录的流量数目,保证记录下来的流量数在后期是收敛的,不会无限增加。
-
记录流量重复次数,可以用于后续生成用例,我们认为重复更多次数的流量其重要性越大。
通过多重策略,来保证我们能够筛选出“优质”的流量用于后续接口测试。
五、总结及其他
目前本方案已经为多个服务(包括微视、企鹅号等)生成多条接口测试用例,已经超过1000条合入到服务中在日常mr中进行接口测试。











- 联系人:阿道
- 联系方式: 17762006160
- 地址:青岛市黄岛区长江西路118号青铁广场18楼