
性能测试之k6篇
- 2022-06-27 10:00:00
- 瞿勋/涂佳瑶
- 转贴:
- 公众号
- 14903
项目的目标是为客户交付一个ToC的APP,其后端是基于RESTful的微服务架构,同时后端还采用了Protobuf协议来提高传输效率。在最终上线之前,我们需要执行性能测试以确定系统在正常和预期峰值负载条件下的表现,从而识别应用程序的最大运行容量以及存在的瓶颈,并针对性能问题进行优化以提升用户体验。
性能测试是一个较为复杂的任务,包括确定性能测试目标,工具选择,脚本开发,CI集成,结果分析,性能调优等过程,需要QA,Dev,Devops协力合作。本文将对这一系列过程进行详细描述。
在得知需要做性能测试后,我们就开始针对性能测试做了一番调研,在阅读了一些性能测试工具对比的文章后,最终挑选了k6,locust和Gatling做了进一步对比,下面是对比的结果。

对我们来说,k6的优势在于:
-
k6支持TypeScript,由于项目上已经有TypeScript使用经验,因此该工具学习成本相对更少
-
k6本身支持metrics的输出,可以满足大部分metrics的需求,有需要还可以进行自定义
-
k6官方支持与多种CI工具,数据可视化系统的集成,开箱即用
-
Gatling支持Scala/Java/Kotlin,项目上没有使用相关的技术栈,需要和客户申请,成本高于k6
有了上面的基础,我们便开始尝试在项目中集成k6,在选了一个简单的API写第一个case的时候,发现有以下一些挑战需要解决:
挑战1-获取Access Token和保证token时效性
由于当前项目的API都集成了OAuth,任何操作都要有一个有效的用户和Access Token,因此需要提前生成token和测试数据。这一部分因为项目的不同会有一些差异,需要具体情况具体分析。在此次测试中具体包括以下几项:
-
用户账号准备,比如生成200个用户,并进行一系列的前置处理,让它们变成可用的正常测试账号,并且需根据项目安全规范,保存到合适地方,比如AWS Secrets Manager或者AWS Parameter Store,这里的账号可以复用。
-
token生成,运行测试前,生成最新的有效token,执行测试的时候只需要去读取token数据。
-
token刷新,由于token基本上都具有时效性,如果有效时间短,还需要考虑renew token,这里我们采用refresh token去获取新access token的方式。
-
需要注意的是测试过程中刷新token会计入请求,对性能测试数据会有些许影响,刷新机制需要纳入考虑范围。
挑战2-Protobuf数据的编解码
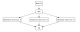
下图简要说明了前后端的架构,Mobile和BFF是以Protobuf格式做数据交换,BFF和Backend是以Json格式做数据交换。

我们的性能测试是针对BFF的,因此需要根据项目中定义的Protobuf格式对请求数据进行编码再发送给BFF,从BFF接受到响应数据时也需要根据Protobuf定义的响应格式进行解码,从而解析出想要的数据。
另外由于性能测试采用的是TypeScript语言,我们还需要将Protobuf文件编译成TS版本,这一点在Protobuf官方文档上给出了解决办法,可以很容易的生成TS版本代码。
由于每个API的编解码结构都是一份单独的proto,因此还涉及到代码复用的问题,需要设计合适的方法,让不同的API只需要提供对应的encode和decode schema即可。
当解决掉前面的两个挑战后,可以初步得到符合项目需求的测试框架。
测试用例设计
当测试case逐渐增多后,我们对测试用例进行了多次的调整,例如对API进行了分类,并通过不同的方式来对他们进行性能测试。
独立API
独立API是指不依赖其他接口提供参数输入,即可完成请求的API,例如部分Get类API。
非独立API
非独立API是指依赖于其他API结果作为参数输入才可完成请求的API,例如部分Put、Delete类API。由于此类API依赖于其他API的结果数据,无法单独做性能测试,在本次性能测试中以整体journey的形式来测这些非独立的API,在测试case中将前一步的结果传给后一步,从而完成整体的journey测试。
我们通过一个例子来说明,我们的test case目录结构如下:
其中
-
对于createOrder,getOrders是独立API,可以方便的进行单个API调用,直接进行测试即可
-
对于updateOder,它依赖于createOrder的结果,所以我们将它们组合起来在Journey中测试,orderJourneyTest里面可以组合createOrder -> getOrder -> updateOrder
k6的executor选择
k6提供了多个executor,不同的executor会以不同的方式去执行测试。我们可以根据项目的需求来选择不同的executor来执行测试。

让性能测试在CI上跑起来-集成TeamCity
k6官方提供了目前主流CI工具的How to文档,非常容易上手。
唯一需要注意的点就是需要手动设置thresholds,当性能结果不达标时,k6会返回非0让CI知道test失败。
展示报告-集成New Relic
数据的采集
k6支持多种数据数据可视化工具,例如Datadog,New Relic,Grafana等,加个参数就可以轻松搞定。我们用的是New Relic,通过K6_STATSD_ENABLE_TAGS=true配置,可以方便的通过k6提供的tag进行数据分类,分类统计不同API,Journey的性能数据。
指标的展示
指标展示主要是在数据可视化平台上,通过自定义各种图表展示性能指标
指标的核对
这里其实是对上面的指标进行核对,以保证我们设置的指标是准确的,为后续性能分析做准备
测试执行
在执行测试时,我们需要分析出影响性能的因素,并尽量控制变量,从而对多次的执行结果进行对比分析,例如都在pipeline上执行来减少网络影响,定期检查数据库数据量,关注K8s的pod数量等等。结合我们的项目特点,我们总结了以下一些因素:
-
数据库数据量
我们系统从架构上来比较简单清晰,后端用到了AWS DynamoDB,所以数据量会对性能有较大的影响,特别是查询类,计算类的API,这里就需要了解用户各个维度的数据量,比如每个月,每天等。
-
请求的body大小
这主要是针对post和put类接口,因为涉及到文件上传,所以文件大小也会对性能有较大影响,需要了解正常用户使用场景下,附件的大小范围
-
K8s pod数量,开启了HPA会触发Auto Scaling
测试中发现性能不稳定,后来发现是UAT环境开启了HPA会触发Auto Scaling,所以在执行测试时,需要考虑不同的场景:
-
测试固定pod下的性能,方便优化对比性能
-
测试Auto Scaling的Policy有效性
-
网络影响
这是一个比较通用的问题,测试时应注意网络变化对性能指标的影响,防止变量太多,性能数据分析不准确
-
不同API的性能差距较大
这里主要是用例设计时需要考虑,k6会统计所有的请求数据,导致API之间会相互影响,数据失真
-
比如token获取的数据也会被收集,导致实际的业务接口数据受到影响
-
再者像delete类的接口,对create有依赖,如果把两个API一起测试,create API的性能数据与delete API差距较大,导致delete接口的数据严重失真。可以通过tag进行筛选,拿到单个API的部分数据,比如response time, 这种还是有意义的,像是rps这种数据,如果两个一起跑的,主要还是取决于create,这样收集到的rps对delete来说意义不大了
-
多个后端API间的相互影响,例如文件上传对性能的影响
由于我们是有BFF和BE,BFF会组合多个BE,所以需要识别多个BE之间的相互影响,尽量保证能准确的测试到目标,减少其他API的影响。比如在准备单独测试某个服务时,可以考虑不添加文件,避免文件服务的干扰
结果分析及优化
对于结果分析来说,k6自身提供了丰富的Metrics可供查看,并且我们也集成了New Relic,因此可结合这两者来进行数据收集,分析及调优。

原图链接:https://k6.io/docs/static/f9df206f5a86e9b4c59d2bdb6a9e351f/485a2/new-relic-dashboard.webp
如上图所示,New Relic可以将收集到的数据以图的形式展示出来,并且我们可以按照需求来定制化Report,这里不仅仅可以用k6收集的数据,还可以叠加一些APM的数据,比如CPU,Memory,Pod数量等信息。通过鼠标定位横坐标上的某一个点,可以清晰的看到该时刻对应的并发量,总请求数,响应时间,失败率等等数据。
另外,在执行测试时,我们通过在控制变量的前提下,进行横向对比,将同类API在相同的配置下,对性能数据进行比较,如果数据相差明显,则可以进一步调查。也可以通过工具对请求进行深入调查,拆解请求中各个模块的耗时,找到最终的原因。
这里举两个例子来说明这个过程。
案例1 - 某获取配置类信息API
此API逻辑比较简单,主要是读取一些配置信息,然后做一些简单的处理返回即可。
运行完测试后,http_req_duration的平均值大概在1s左右,平均rps在108左右,而且VU最高达到了300,说明此时已经拉满了用户,还有0.7%的错误。而其他需要查询数据库的API同样的设置下,http_req_duration只有23ms,rps有204,VU最高才到76。这个API只是取一些配置信息,没有其他太复杂的操作,也不用访问数据库,显然这个性能数据是异常的,于是拉着Dev一起先排查一下逻辑,发现是配置文件内容的缓存逻辑有问题,每次请求都会去读配置文件,导致性能数据异常。
在修改完之后,相同配置下,http_req_duration为12ms,平均rps为145,VU最高为50,错误率为0,很显然,这个数据说明我们还可以继续加大Rate,当把Rate加到500时,平均的http_req_duration依旧是12ms,VU最大也才80,依旧没有到达瓶颈,由此可见修改后性能提升非常明显。
案例2 - 某getAPI
这个API是一个get类型的API,职责是去数据库中获取一个值,没有其他额外操作。
运行完测试后,http_req_duration的平均值大概在320ms左右,横向对比其他get API能够发现duration的结果是非常不合理的。但是k6只给出最后的运行结果,我们无法从这些结果中得知具体的问题在哪。好在new relic上提供了一些具体的API信息,其中有一项中提供了API的详细调用流程,以及每一流程中花费的具体时间。由于项目安全需要,这里以new relic提供的图为例。

原图链接:https://docs.newrelic.com/static/distributed-tracing-trace-details-page-1c064ef6a7607f95be583786b6af9251.png
从图中,可以清楚的看到API的service调用流程图,以及与不同的service互相call的个数。并还能清楚地看到每一步花费的时间,从而找到最费时间的那一步调用。
最后根据这个图,我们发现原本只是去数据库取一个值回来,却由于实现方式不对,导致了和数据库之间产生了200多个call。这才使得response time高达320ms。经过重新编码后,该API的response time降到了20ms,性能提升了15倍。
此次性能测试复杂度较高,非一两人之力能够完成,作为QA,我们可以主导事情的发生,并成为其中的主力承担者,要及时提出问题和寻求帮助,通过团队的协作,让问题尽快得到解决,最终顺利完成性能测试任务。


- 联系人:阿道
- 联系方式: 17762006160
- 地址:青岛市黄岛区长江西路118号青铁广场18楼